

How I use git

Recently I tried to explain to a colleague my mental model for when to put something in the same pull request and when not to. I caught myself saying “well, except…” a few times, I decided to write down how I use git — to examine my idiosyncracies, see where I could improve, and possibly share something useful.
Since this is the Internet, let me add the disclaimer right here at the top: how I use git is based on the last 12 years of working in companies with smallish (less than 50) engineering teams. In every team, we used git and GitHub exclusively; changes were made in branches, proposed as pull requests, and then merged into the main branch. In the last few years, after GitHub introduced squash-merging, we used that.
I’ve never used any other version control system. I’m unable to and won’t compare git to Mercurial, jj, Sapling, ….
With that out of the way, here’s how I use git.

Technicalities
Everything is in git, all the time. Every side-project, large or small, finished or abandoned, is in a git repository. Running git init is the first thing I do in a new folder. I do not know why I wouldn’t use git if I could.
The git part is the most important piece in my shell prompt. I feel naked when I don’t have it. It shows the current branch and whether the repository is dirty, i.e. whether it has uncommitted changes:

When someone asks me to help them with some git thing and I notice that they don’t have git information in their shell prompt, that’s the first thing I tell them to do.
I use git on the CLI 99.9% of the time. I never used a GUI for git and don’t see a reason to.
The exception: git blame. For that I always use built-in editor support or the GitHub UI. Previously and for over a decade I used vim-fugitive’s blame functionality. Now: the git blame support we added to Zed.
I use git aliases and shell aliases as if possible future athritis were standing behind me, whispering “soon” into my ear, waiting for every wasted keystroke. They are stored in ~/.gitconfig and my .zshrc. My most used aliases, according to atuin:
gst - for `git status`
gc — for `git commit`
co — for `git checkout`
gaa — for `git add -A`
gd — for `git diff`
gdc — for `git diff —cached`I spam these. There’s a direct connection between muscle memory and the keyboard, no brain involved. Especially gst, for git status — I constantly run this as confirmation that whatever I did worked. I git add some files and run gst, I git add -p some files and run gst and gdc, I git restore and gst, I git stash and gst.
Here, for example, is how I check what changes I just made, stage them, and commit them:
~/code/projects/tucanty fix-clippy X φ gst
# [...]
~/code/projects/tucanty fix-clippy X φ gd
# [...]
~/code/projects/tucanty fix-clippy X φ gaa
~/code/projects/tucanty fix-clippy X φ gst
# [...]
~/code/projects/tucanty fix-clippy X φ gdc
# [...]
~/code/projects/tucanty fix-clippy X φ gc -m "Fix clippy warnings"
~/code/projects/tucanty fix-clippy OK φ gst
# [...]Why? I’m honestly not sure — maybe it’s the lack of feedback from the git commands, maybe because the prompt doesn’t tell me everything, I don’t have a UI and gst is the de-facto UI?
I use this pretty_git_log function in ~/.githelpers a hundred times every day. I got it from this Gary Bernhardt screencast and haven’t changed it in 12 years. It looks like this:
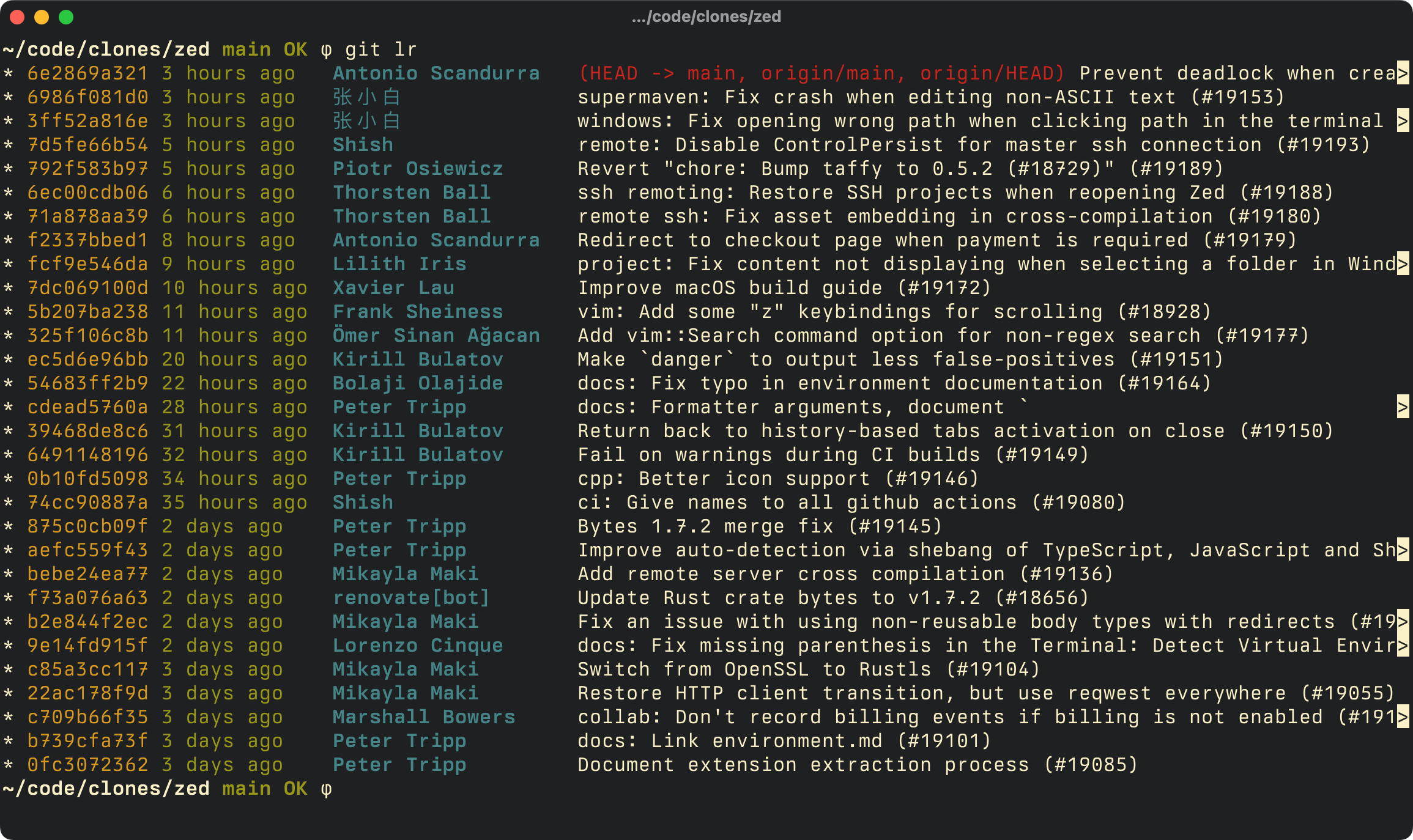
(Is there a reason why git lr is not aliases to glr? No, except that I’m lazy and would probably never pick up the alias after years of git lr.)

Committing
What I commit and how often I commit is guided by what ends up on the main branch of the repository I’m working in. Is it a commit? A squash commit? Or a series of commits? That’s what I optimize for.
What ends up on the main branch has to be
Easy to understand by others as a self-contained change.
Revertable. If I made a mistake while making the change and I realise that after merging it, can I revert my change with a
git revertor will that also revert 12 other unrelated changes that very likely won’t be an issue?Bisectable. If we notice that a regression slipped into the main branch in the last week, will that regression be easy to find if we go through each commit and test them? Or will we end up saying “this commit introduced it” with the commit in question being 3k changed lines that updated an OpenSSL dependency, changed marketing copy, tweaked the timeout settings of the default HTTP client, added a database migration, changed business logic, and updated the default logger? That’s something I want to avoid.
I don’t think all three are 100% achievable all the time, but the general ideas — is something easy to undo? is something easy to debug as a potential regression? — I try to keep in mind when deciding whether to put something in a separate pull request, or a separate commit.
I commit early and commit often. My mental model for a commit: a quicksave in a video game. You survived those three zombies hidden behind the corner? Quicksave. You fixed that nasty bug that required changes that you don’t really understand yet but it works? Quicksave. Quicksave and then worry about doing it properly.
I see commits and their history in my branch as malleable. I can always reword them, squash them, rebase them — as long as I haven’t asked someone for review, as long as they’re still “mine.”
Why? Because in nearly every repository I worked in (except for open-source repositories I contributed to), the merged pull request is the thing that ends up on the main branch, not the commit.
So I commit as much as I want, when I want, and then make sure that the merged pull request is optimized for ease of understanding, revertability, bisectability. That brings us to…

Pull Requests
The merged pull request is more important than a commit made on a branch, because that’s what ends up on the main branch and that’s what I want to optimize for.
If we use squashed commits when merging, then merging a PR results in a single commit and I will worry about what that single commit will look like and if that commit is easy to understand, easy to revert, easy to bisect.
If we don’t use squashed commits, but instead merge all commits from a branch into the main branch, then I will worry about those commits. In that case I might do interactive rebasing on my branch and squash my commits as needed into single units of works so that they in turn are easy to understand, revert, bisect.
Reviews create exceptions to this rule. Because reviewers’ or colleagues’ needs trump my own. For example, if the PR is reviewed commit by commit, I'll put effort in the commits. If the PR is reviewed as a single change, with 3 lines in 2 files changed, I'm happy to add a "fix formatting" commit, and ignore the message.
The general rule stands though: I only really care about the final PR and how it's reviewed and what it will turn into once it’s merged, not the single commits that lead up to the review and the merge.
I open PRs very early. As early as I have the first commit. Previously I marked those PRs as “WIP” by putting that as a prefix in the PR title, but nowadays we have the draft status in GitHub. I open them early, because after I push, while I keep working, CI is already kicking off and running. I get feedback from longer-running test suites, linters, style checks, and other things that run in CI, while I continue to work.
My mantra for pull requests: small PRs, eagerly merged. Sometimes they’re 3 lines. Sometimes 300. Basically never 3000. If they’re open for more than a week, that’s a warning sign.
Example: say I’m working on a feature that changes how user settings are displayed in the UI. While working on that, I notice that I need to change how user settings are parsed. It’s a two-line change. I will put that two-line change in a separate PR, separate from the UI changes even if that’s where I found the need to make the change. Why? Because if two days later someone says “something’s wrong with our settings parser”, I want to be able to directly point to either the UI change or the parsing change and revert one or the other.
I rebase my PRs on top of the main branch and don't merge the main branch back into mine. Why? Because when I use git lr (my alias to show the git log in my branch) I just want to see the commits made on my branch. I think it’s cleaner to be rebased on the latest main. I don’t like having merge commits in my branch. An interactive rebase also allows me to look at all commits I made and get a feel for what’s on the branch.
When I rebase, do I not worry about destroying the original, pristine commit history? Again: the unit of work is the merged PR and I don’t care whether the commits inside my branch reflect what happened in real time. What matters is what ends up on the main branch and if we use squashed commits, then all that pristine commit history will get lost anyway.
But, again, exceptions are made by reviews and the requirements of reviewers — I sometimes rebase interactively in my branch to squash or edit commits to make them easier to review (for myself and others), even though, again, I know that those commits will get squashed two hours later.
I also use pull requests in my side-projects even if I’m the only person working on that project and even if I will forever be the only person working on it. I don’t do it for every change, but sometimes, because I like keeping track of some bigger changes in GitHub’s UI. I guess I do use a UI?

Commit Messages & Pull Request Messages
I care about commit messages, but not too much. I don't care about the prefixes and formulas etc. I do care about well written messages. I read Tim Pope’s A Note About Git Commit Messages in, what?, 2011, and haven’t forgotten about it since.
If we’re doing squashed commits when merging, then the PR description is often the message for the resulting PR and I make sure to put effort into the PR message.
The most important thing about a git commit message or a pull request message is the Why behind a change. I can see the What in the diff (although sometimes a short explanation in the message helps), but what I want to know when I end up reading your commit message is Why you made the change. Because usually, when reading commit messages, isn’t not because something good happened.
I think things like Conventional Commits are largely a waste of time. Teams end up bike-shedding the right commit prefixes for very little benefit. When I’m hunting down a regression through the commit history, I’m going to look at every commit anyway, because we all know that yes, a regression can even hide in a [chore]: fix formatting commit.
I do sometimes add prefixes to commit messages or pull request titles, like “lsp: “ or “cli: “ or “migrations: “. But I mostly do that to keep the message short. “lsp: Ensure process is cleaned up” is shorter than “Ensure language server process is cleaned up” and conveys the same thing basically.
If possible I try to have a demo video in the PR, or a screenshot. A screenshot is worth a thousand words and ten thousand links to other tickets. A screenshot is proof. Proof that it actually fixes what you said it would fix, proof that you actually ran the code. It also takes far less time than people usually think it does. Here’s an example:

If needed I reference other commits and pull requests in messages. The idea: leave breadcrumbs. Instead of “Fixes parsing not working” I try to write “Fixes parsing not working, after the change in 3bac3ed introduced a new keyword”
At Zed, when pairing, we add `Co-authored-by: firstname <email>` to our commit messages so that the commit is attached to multiple people. Like this:

With commit messages especially, it’s all about context, context, context. When I'm working alone I use different commit messages than when I'm working with a team. When we're doing reviews it's different than when pairing.
Who are you talking to with your commit message and when and why? That’s the question that should influence the message.
When I’m alone in my own personal repository, trying to get CI running, you can bet on single-letter commit messages showing up on main. But even when I’m alone, if I fixed a really nasty bug, I’ll write a nice message. When I’m working with others, I try to write commit messages that explain to them what I was trying to do and why.

Reviews
Before I ask someone to review my PR, I read through the diff on the pull request page myself. Something about it being not in your editor makes you spot more bugs and left-over print statements.
I try not to ask for reviews when CI isn’t green. Exception: I know how to fix CI already and we can parallelize by reviewer starting while I fix CI.
When I review someone elses code, I always try to check out the code and run it and test that it actually does what the pull request message says. You’d be surprised by how often it doesn’t.

Workflows
The basic workflow is always the same when I’m working with others: open a branch off of the main branch, start working, commit early & often, push early & often, open a pull request as a draft as soon as possible, finish work, make sure the commits in the branch somewhat make sense, ask for a review, merge.
When I’m working alone, I commit on the main branch 99% of the time and push after each commit.
Sometimes, when working on a branch, I notice that I need to make a new commit in a separate branch so that I can turn it into a separate pull request. There are multiple different strategies that I use here.
git add -p && git stashthe things that I later want to commit on this branch, branch A, then switch to a new branch, B, that’s branched-off of main branch, make a commit there, and push.git add -p && git commitwhat I want to keep on the branch.git stashthe things I want to put on a different branch, switch branches,git stash pop, commit.git add -p && git commit -m “WIP”what I want to keep on the branch. Then, again, stash the things I want on another branch, go there, commit them. Then go back to original branch, undo the “WIP” commit by doinggit reset —soft HEAD~1, go back to work.git add -pwhat I want to move to another branch, thengit stash, thengit reset —hard HEAD, to throw away every other change I have made on that branch, because it’s not worth keeping it around. Then switch branches,git stash pop, commit.Sometimes I even turn changes I want into two commits on the same branch, then switch branches,
git cherry-pickone of the two commits over, go back to the old branch, dogit rebase -iand drop the commit that’s already moved over.
When do I chose one strategy over the other? It depends on how big the change I want to make on another branch is and how much I uncommitted things I have in my working directory.
I don’t care that much about branch names, as long as they make some sense. I use the GitHub UI to get an overview of my currently open pull requests (this URL is a quicklink in Raycast, so I can just type “prs” in Raycast and open the URL.) That helps me to know what PRs I currently have in flight and which ones are ready to merge.
I either create pull requests by clicking that URL that’s printed after git pushing to GitHub, or by running gh pr create -w. That’s really the only thing that I use the GitHub CLI for.
The other thing that I use gh for is to switch between open pull request branches. Especially when I check out contributors’ pull requests, which sit in a fork.
I also have these two, very neat aliases to fuzzy-switch between my open PRs and wish I would remember them more often.
It’s been many years since I last had to delete and reclone a repository because of git problems. Nowadays I can wiggle my way out of most problems that could show up by using the git reflog, a bit of git reset, and some duct tape.

It’s all there
You can see all my work of the last 5 years on GitHub:
Here’s 1368 merged pull requests in sourcegraph/sourcegraph-public-snapshots.
Here’s 195 merged pull requests in sourcegraph/src-cli.
Here’s 391 merged pull requests in zed-industries/zed.

If you click on those links and then look through my PRs you will find that I’m not 100% consistent with everything I wrote here.
Depending on the context — how big is the change, how risky is the change, who am I working with, how often have I tested it, when is the next release, who reviewed my code — I put a lot of effort into how I use git or not. I’ve written some very thorough, highly-detailed, technical commit messages and I wrote one-liners with swear words (sometimes that’s all the line contained.)
And that’s it — how I use git!
Nice! Thanks for the article!
I do my commits like this:
`$ c feat: your commit message`
c being my bash function which looks like this:
`c() { git add --all; git commit -m "$*"; }`
This let's me stage and commit without having to put the message in quotes.
Don't mean to hog the light here as it's your article so feel free to remove my link, but if you're interested this is the list of my git alises/functions I use: https://gist.github.com/matzar/3a8e8b4d28429d62420689a894583247
Thank you for sharing! It’s given me the inspiration to revisit my aliases. I avoided them for some time whilst working with devs who were new git, but there’s probably a happy medium that echos out the actual command being run, and maybe it even runs a ‘gst‘ afterwards.
I’ve always found consistent implementation of Co-authoring across our teams tricky, possibly due to remembering the format, and found that when we leant on tools such as GitHub desktop, we were better at keeping this up (it’s a couple of button clicks). Would you any have any tips to getting this working well and consistently with others?