

From 1s to 4ms
So zero-cost abstractions exist?

When Zed was open-sourced, someone on HackerNews commented that Sublime Text is faster when searching for all occurrences of the current word in a buffer. Zed takes 1s and Sublime somewhere around 200ms.
Searching all occurrences means: you position your cursor over a word, you hit cmd-shift-l and all occurrences of that word in the current buffer are selected and you get a cursor at each occurrence, ready to play some multi-cursor rock’n’roll.
Here, watch this:
So, Sublime does this in 200ms and Zed takes 1s? Huh.
Antonio, one of Zed’s co-founders, immediately and confidently said “we can make this faster.” My not-yet-too-familiar-with-the-codebase mind silently asked “can we?” before we dove in. Little did my mind know.
We looked at the code in question. Here it is, in its original, takes-1s form:
pub fn select_all_matches(
&mut self,
action: &SelectAllMatches,
cx: &mut ViewContext<Self>
) -> Result<()> {
self.push_to_selection_history();
let display_map = self.display_map.update(cx, |map, cx| map.snapshot(cx));
loop {
self.select_next_match_internal(&display_map, action.replace_newest, cx)?;
if self.select_next_state.as_ref().map(|selection_state| selection_state.done).unwrap_or(true)
{
break;
}
}
Ok(())
}Ignore the details. What’s important is that keyword right in the middle: loop. The code is probably what many people would naturally do to implement a select_all_matches method: use the select_next_match in a loop until there’s no more matches to select. Voilà, all matches selected.
When looking at it with Antonio, I knew this code as well as you do right now, but he knew what’s going on under the hood. His idea: optimize it by inlining what select_next_match_internal does and then do it in batches.
It’s similar to how you’d optimize an N+1 query in a web application. Instead of doing something like this in your request path:
loop {
user = loadNextUser()
if user == null {
break
}
profilePicture = loadUserProfilePicture(user)
blogPosts = loadLastFiveBlogPosts(user)
render_template("user_profile", user)
}you would do this:
users = loadAllUsers()
pictures = loadUserProfilePicturesForUsers(users)
blogPosts = loadLastFiveBlogPostsForUsers(users)
for user in users {
render_template("user_profile", user)
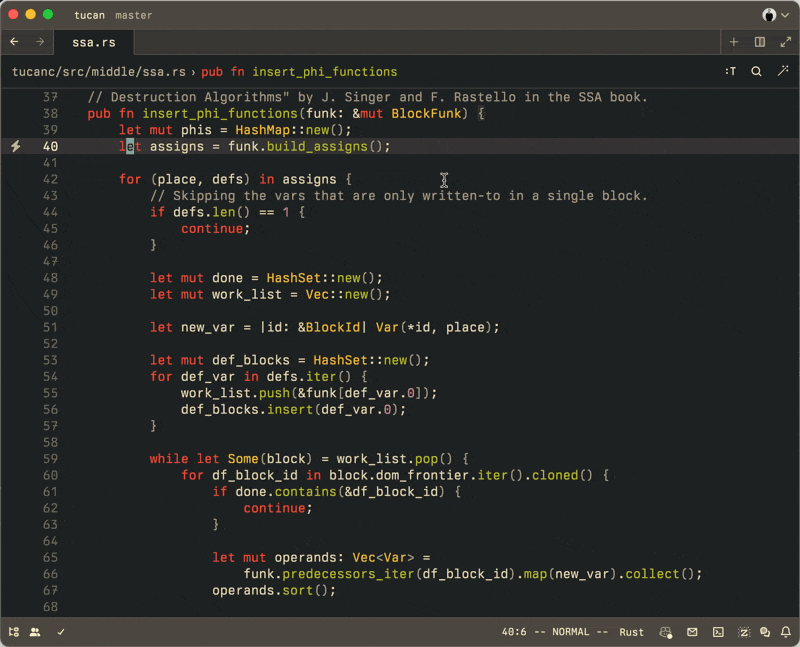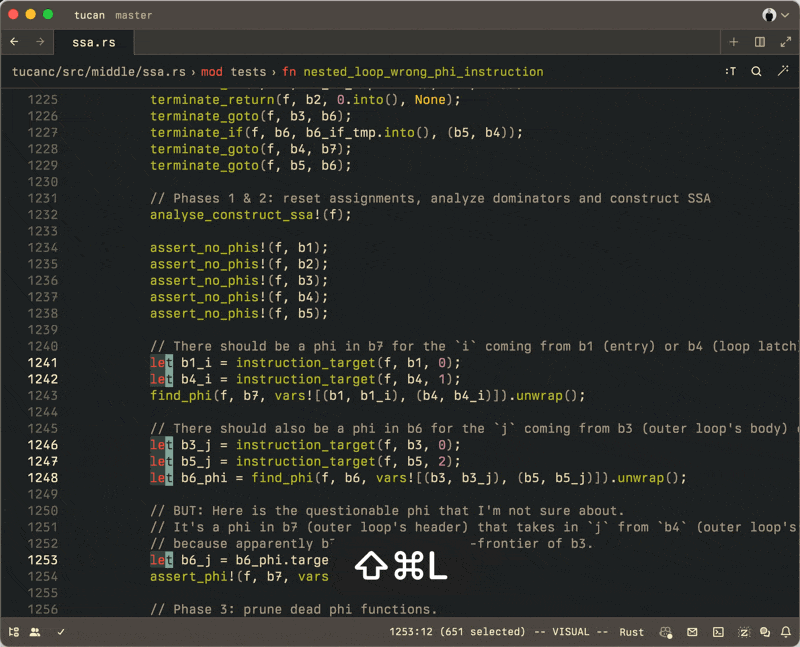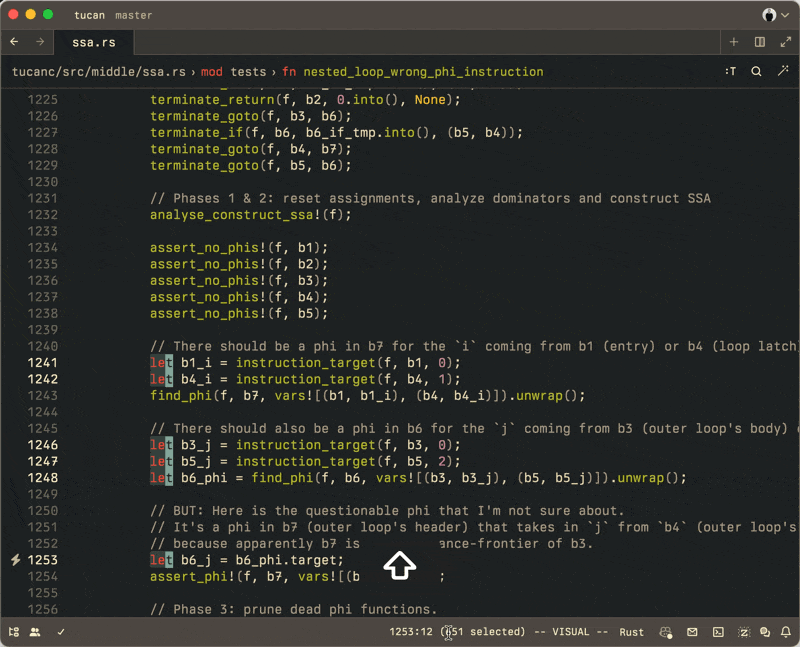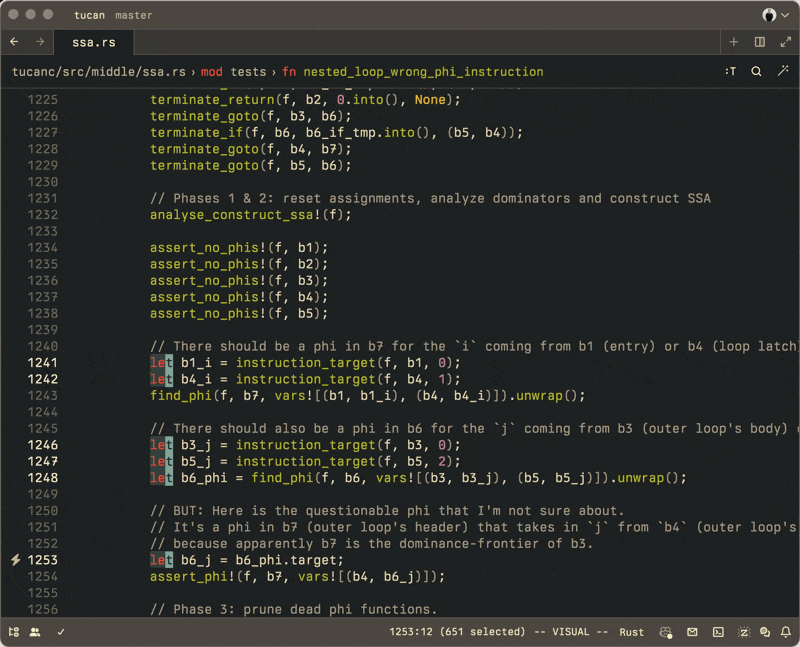
}Or something like that. You get the idea.
And that’s what we did with that piece of code from above. I’m going to show you what we ended up with, but before you look at the code, keep in mind the following: don’t worry about the details! Just read the code like you’d read instructions for a new toothbrush: confident you don’t need know the line-by-line, but curious nonetheless (because, hey, maybe you’ve done it wrong all your life):
pub fn select_all_matches(
&mut self,
_action: &SelectAllMatches,
cx: &mut ViewContext<Self>,
) -> Result<()> {
self.push_to_selection_history();
let display_map = self.display_map.update(cx, |map, cx| map.snapshot(cx));
self.select_next_match_internal(&display_map, false, None, cx)?;
let Some(select_next_state) = self.select_next_state.as_mut() else {
return Ok(());
};
if select_next_state.done {
return Ok(());
}
let mut new_selections = self.selections.all::<usize>(cx);
let buffer = &display_map.buffer_snapshot;
let query_matches = select_next_state
.query
.stream_find_iter(buffer.bytes_in_range(0..buffer.len()));
for query_match in query_matches {
let query_match = query_match.unwrap(); // can only fail due to I/O
let offset_range = query_match.start()..query_match.end();
let display_range = offset_range.start.to_display_point(&display_map)
..offset_range.end.to_display_point(&display_map);
if !select_next_state.wordwise
|| (!movement::is_inside_word(&display_map, display_range.start)
&& !movement::is_inside_word(&display_map, display_range.end))
{
self.selections.change_with(cx, |selections| {
new_selections.push(Selection {
id: selections.new_selection_id(),
start: offset_range.start,
end: offset_range.end,
reversed: false,
goal: SelectionGoal::None,
});
});
}
}
new_selections.sort_by_key(|selection| selection.start);
let mut ix = 0;
while ix + 1 < new_selections.len() {
let current_selection = &new_selections[ix];
let next_selection = &new_selections[ix + 1];
if current_selection.range().overlaps(&next_selection.range()) {
if current_selection.id < next_selection.id {
new_selections.remove(ix + 1);
} else {
new_selections.remove(ix);
}
} else {
ix += 1;
}
}
select_next_state.done = true;
self.unfold_ranges(
new_selections.iter().map(|selection| selection.range()),
false, false, cx,
);
self.change_selections(Some(Autoscroll::fit()), cx, |selections| {
selections.select(new_selections)
});
Ok(())
}70 lines of code on an empty stomach without syntax highlighting — I’m sorry. But even if you’ve never seen code that’s similar to this bit here, I’m pretty sure you understood what’s happening:
Check whether we even have a next selection, return if not.
Get all current selections in the buffer (
let mut new_selections = …)Find all matches in the current buffer (
select_next_state.query.stream_find_iter)For each match: add it to
new_selections, modulo some word-boundary checks.Sort the selections and remove overlapping ones.
Unfold code that contains selections.
Change the selections in the editor to the ones we just constructed (
self.change_selections), which causes them to be rendered.
Except for that while-loop in the middle that does some wicked plus-1-ing (that I surely would’ve messed up but Antonio didn’t) — it’s pretty high-level, right?
It doesn’t even look optimized. There’s none of the scars that optimized code usually wears: no secondary data structures to save another loop, no falling-down to raw pointers carnage, no SIMD, no fancy data structures introduced. None of that.
Here’s the thing, though. Here’s why I’m showing you this and why I’ve thought about this code for the last three weeks.
When we ran the optimized code for the first time the runtime went from 1s down to 4ms. 4 milliseconds!
I couldn’t believe it. 4ms! With code that’s still this high-level! With the unfold_ranges call, with finding all the matches, with checking word boundaries, with extending and sorting and possibly dropping and rendering selections — 4ms!
If you’re reading this and shrugging it off with “so what, 4ms is an eternity for computers” then yes, you’re right, 4ms is an eternity for computers, yes, I agree, but based on that reaction I bet that you didn’t grew up like I did as a programmer. See, I grew up building websites, web applications, backends, that kind of stuff and in that world basically nothing takes 4ms. If it takes me 10ms to ping the closest data center in Frankfurt, how can I deliver something to you over the wire in less than that?
So there I was, staring at the 4ms and wondering: is this what the Rust enthusiasts mean when they say zero-cost abstractions? Yes, we’ve all heard that claim before (and yes: maybe too many times) and I’ve also written Rust for years now, so the idea that Rust is fast wasn’t new to me.
But seeing high-level code like this find 2351 occurrences of <span in a 5184 lines XML file that contains the collected poetry of Edgar Allan Poe in 4ms?
I don’t know, man. I think it might have changed me.
4ms could be one whole frame for e-sports games like Valorant, Counter-Strike or Dota... There is a lot of stuff that you can do for 4ms, you can render all raytraced shadows in a frame for 4ms. Now, yeah some types of problems are bottlenecked by bandwidth/CPU communication, but even on CPU side only, 4ms is huge amount of time for computers that are as fast as today's machines. Anyway I like Zed, and I like work you guys do. Wishing you more perf wins, reducing some more miliseconds.
Not a case of "let the compiler do the optimization" :-)
Is this a rust trait? haha